
搭建 Prometheus
阅读 (234184)一、Prometheus介绍
Prometheus(普罗米修斯)是一套开源的监控、报警、时间序列数据库的组合,起始是由SoundCloud公司开发的。随着发展,越来越多公司和组织接受采用Prometheus,社会也十分活跃,他们便将它独立成开源项目,并且有公司来运作。Google SRE的书内也曾提到跟他们BorgMon监控系统相似的实现是Prometheus。现在最常见的Kubernetes容器管理系统中,通常会搭配Prometheus进行监控。
Prometheus基本原理是通过HTTP协议周期性抓取被监控组件的状态,这样做的好处是任意组件只要提供HTTP接口就可以接入监控系统,不需要任何SDK或者其他的集成过程,这样做非常适合虚拟化环境。
组件说明
1.MetricServer:是kubernetes集群资源使用情况的聚合器,收集数据给kubernetes集群内使用,如
kubectl,hpa,scheduler等。
2.PrometheusOperator:是一个系统监测和警报工具箱,用来存储监控数据。
3.NodeExporter:用于各node的关键度量指标状态数据。
4.KubeStateMetrics:收集kubernetes集群内资源对象数据,制定告警规则。
5.Prometheus:采用pull方式收集apiserver,scheduler,controller-manager,kubelet组件数据,通过http协议传输。
6.Grafana:是可视化数据统计和监控平台。
二、grafana介绍
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。它主要有以下六大特点:
1、展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式
2、数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等
3、通知提醒:以可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过Slack、PagerDuty等获得通知
4、混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源
5、注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记
6、过滤器:Ad-hoc过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询。
展示模版下载:
https://grafana.com/grafana/dashboards
三、prometheus部署
git网站:https://github.com/coreos/kube-prometheus
mkdir prometheus
cd prometheus
git clone https://github.com/coreos/kube-prometheus.git
cd kube-prometheus
修改 grafana-service.yaml 文件,使用 nodepode 方式访问 grafana:
vim manifests/grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: grafana
name: grafana
namespace: monitoring
spec:
type: NodePort # 添加内容
ports:
- name: http
port: 3000
targetPort: http
nodePort: 30100 # 添加内容
selector:
app: grafana
修改 prometheus-service.yaml,改为 nodepode
vim manifests/prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: k8s
name: prometheus-k8s
namespace: monitoring
spec:
type: NodePort # 添加内容
ports:
- name: web
port: 9090
targetPort: web
nodePort: 30200 # 添加内容
selector:
app: prometheus
prometheus: k8s
sessionAffinity: ClientIP
修改 alertmanager-service.yaml,改为 nodepode
vim manifests/alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
alertmanager: main
name: alertmanager-main
namespace: monitoring
spec:
type: NodePort # 添加内容
ports:
- name: web
port: 9093
targetPort: web
nodePort: 30300 # 添加内容
selector:
alertmanager: main
app: alertmanager
sessionAffinity: ClientIP
kubectl apply -f manifests/setup
kubectl apply -f manifests/
kubectl get pod -n monitoring
kubectl get svc -n monitoring
稍等两分钟执行:
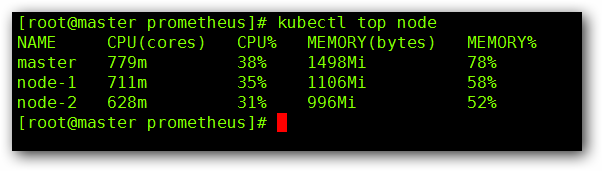
kubectl top node
kubectl top pod
执行完成后查看一下状态,首先是 Pod:

在看下SVC:
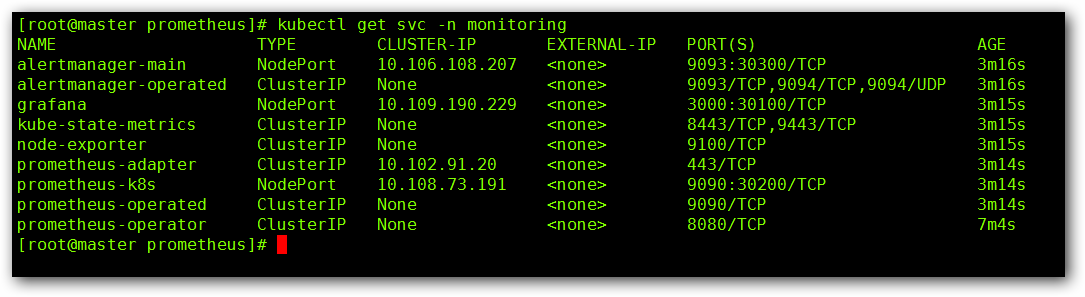
看下收集的 Node 的数据:
访问 prometheus
通过浏览器输入 Master IP : 30200
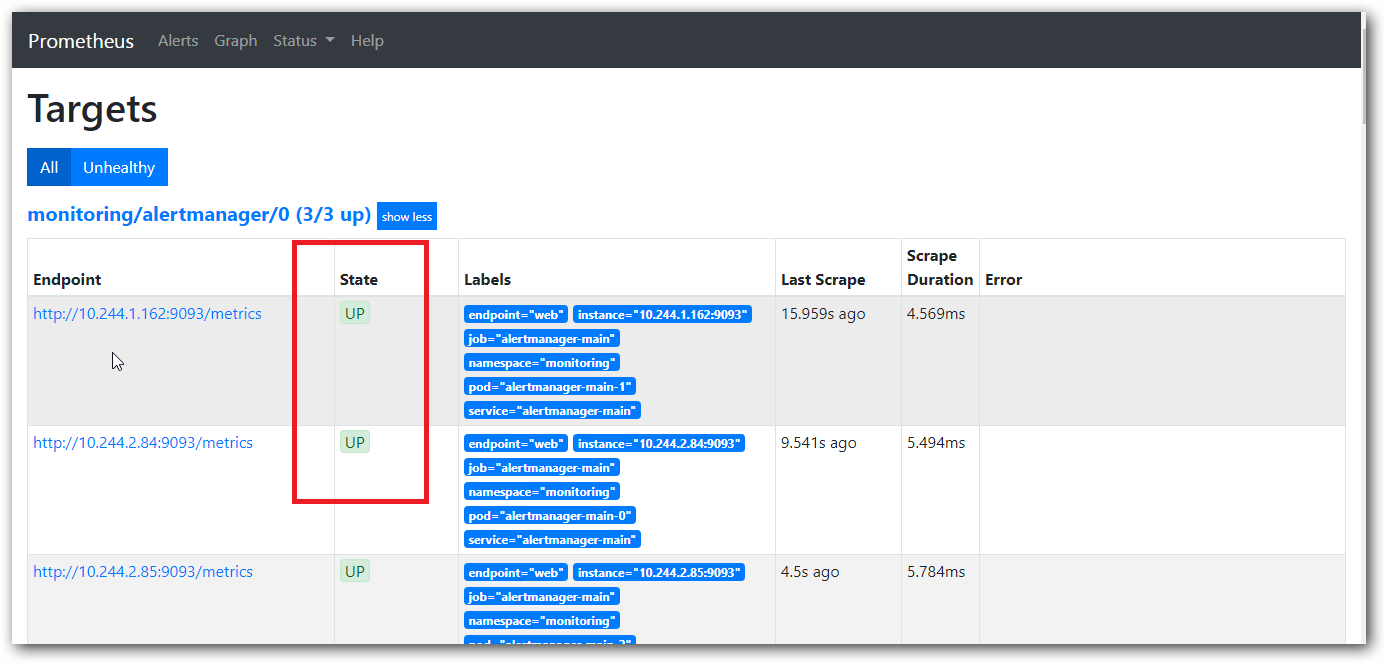
我们可以在 status 下 Targets 里看到我们的节点状态:
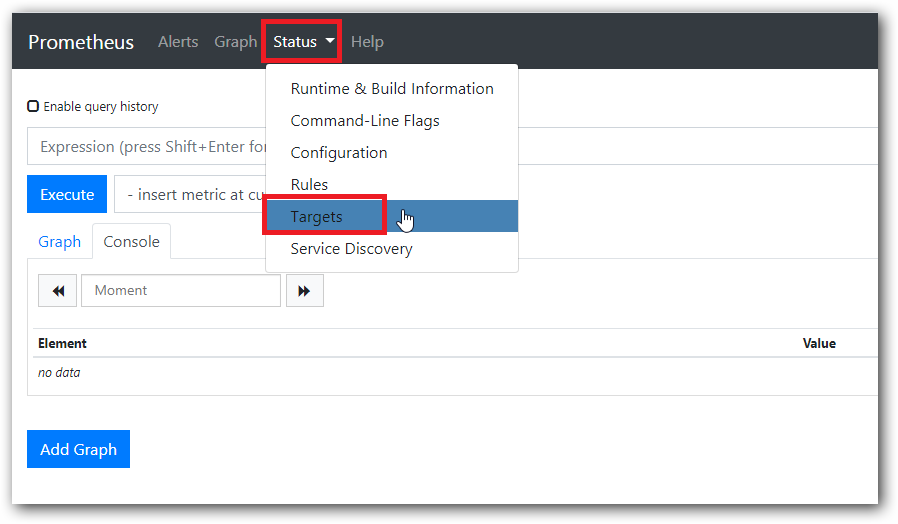
显示 UP 状态 说明我们部署成功:
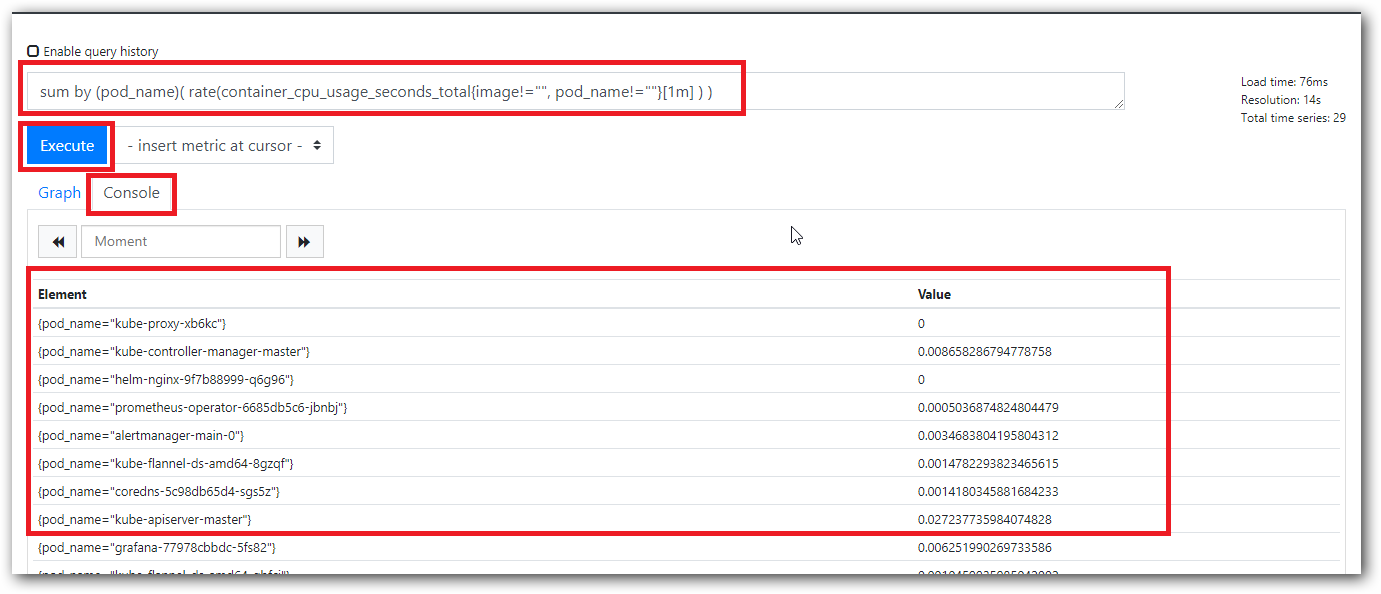
prometheus 的 WEB 界面上提供了基本的查询,查询条件如下:
1.POD内存使用率
sum(container_memory_rss{container!="POD",container!="alermanager",image!="",pod!=""})by(pod) / sum(container_spec_memory_limit_bytes{container!="",container!="POD"})by(pod) * 100 != +inf
2.POD的CPU使用率
sum(rate(container_cpu_usage_seconds_total{image!="",container!="POD",container!=""}[1m])) by (pod,namespace) / (sum(container_spec_cpu_quota{image!="",container!="POD",container!=""}/100000) by (pod,namespace)) * 100
3.POD的文件系统使用量
sum(container_fs_usage_bytes{image!="",container!="POD",container!=""}) by(pod, namespace) / 1024 / 1024 / 1024
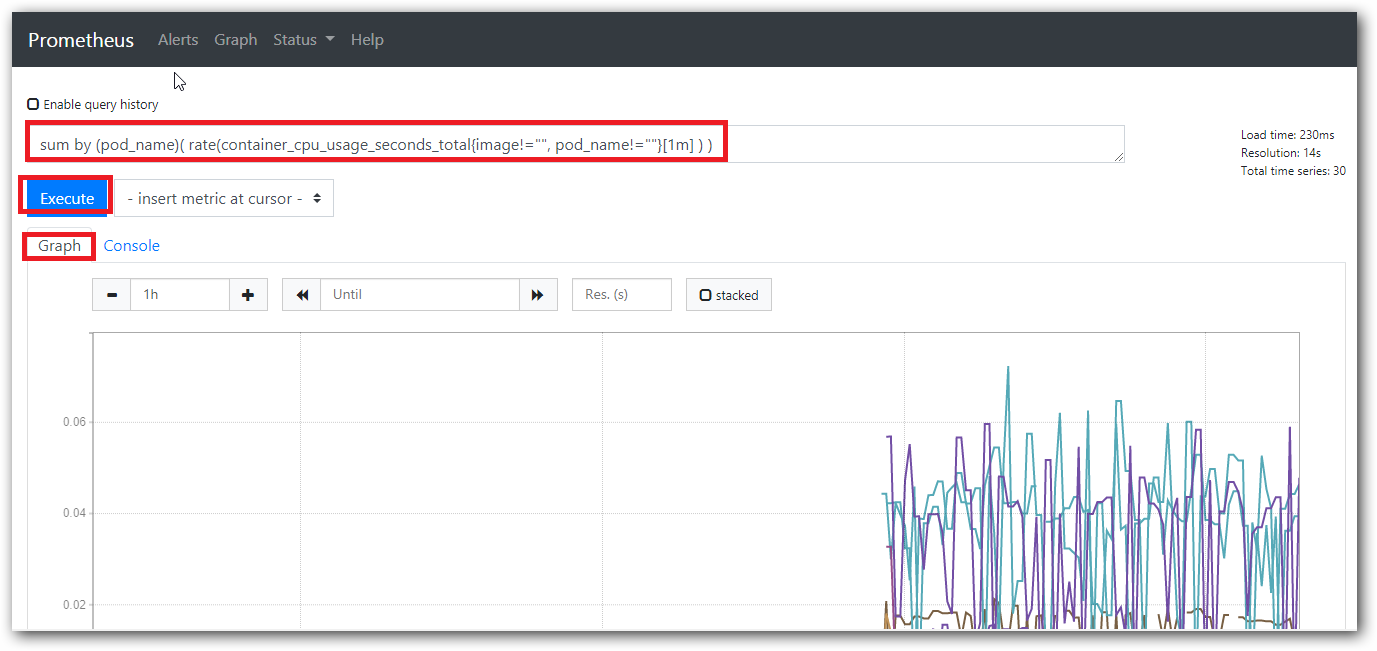
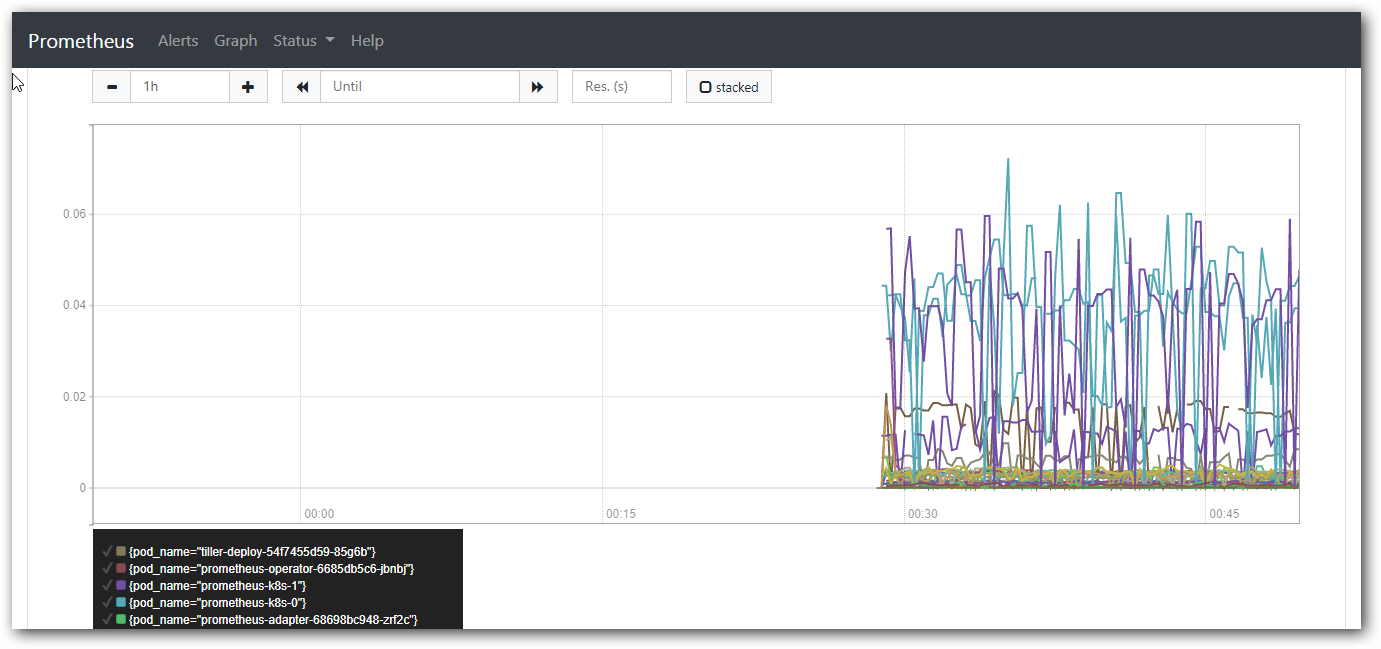
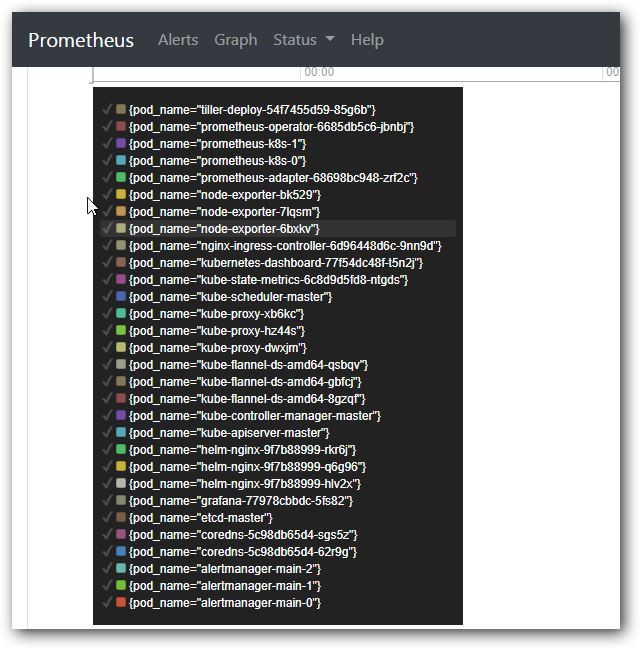
上述的查询有出现数据,说明 node-exporter 往 prometheus 中写入数据正常,接下来我们就可以部署grafana 组件,实现更友好的 webui 展示数据了
访问 grafana
查看 grafana 服务暴露的端口号:
kubectl get service -n monitoring | grep grafana
grafana NodePort 10.109.190.229 <none> 3000:30100/TCP 28m
如上可以看到 grafana 的端口号是 30100,浏览器访问 http://MasterIP:30100 用户名密码默认 admin/admin

修改密码后登陆:
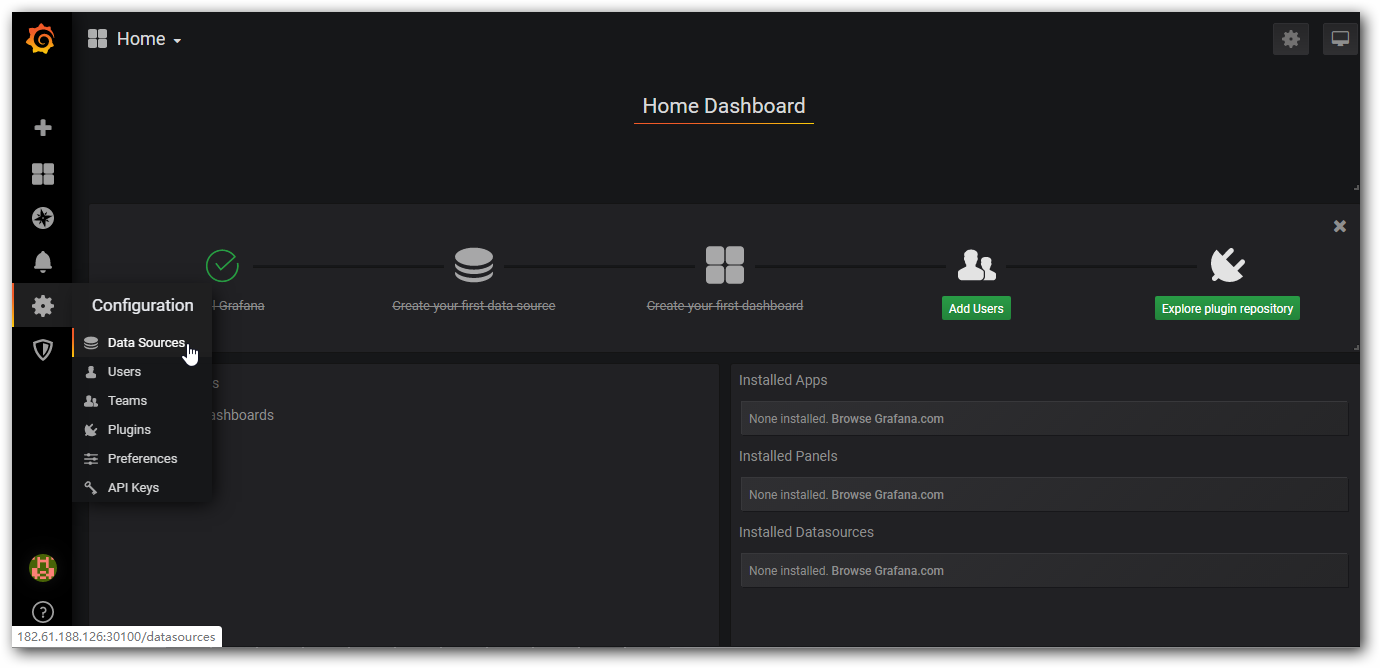
添加数据源
选择模版:
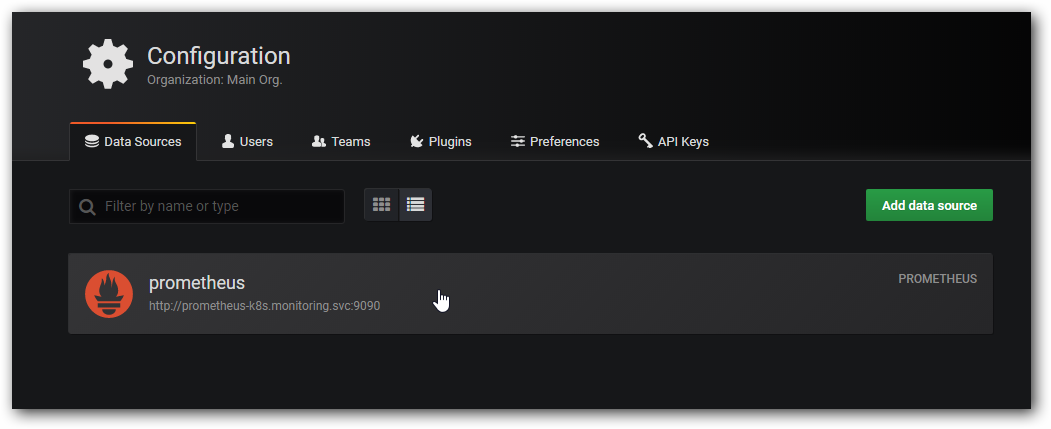
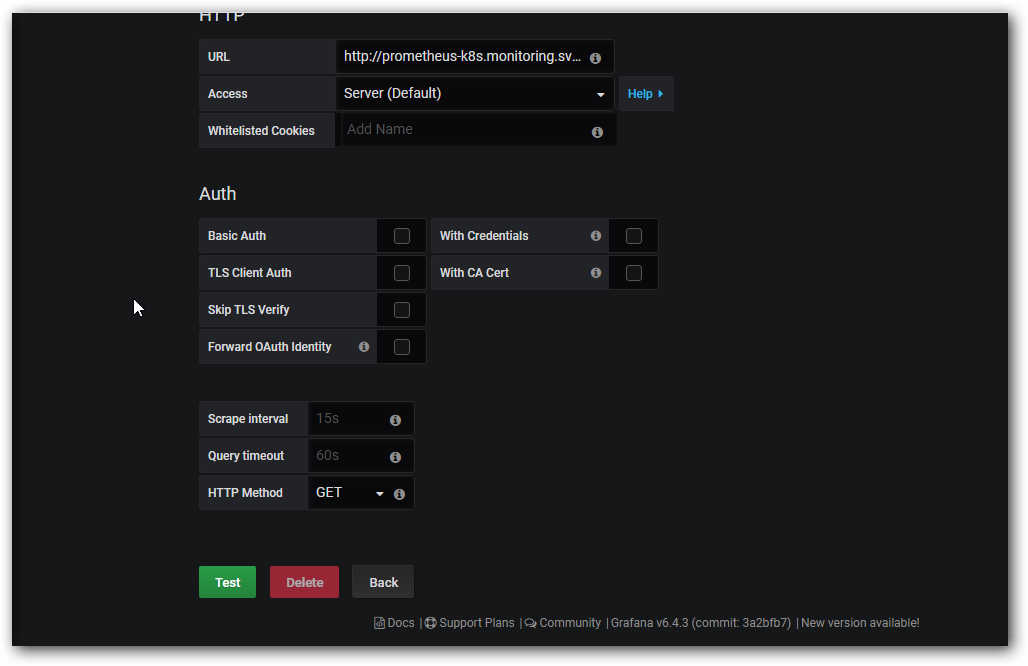
数据信息已经自动填好
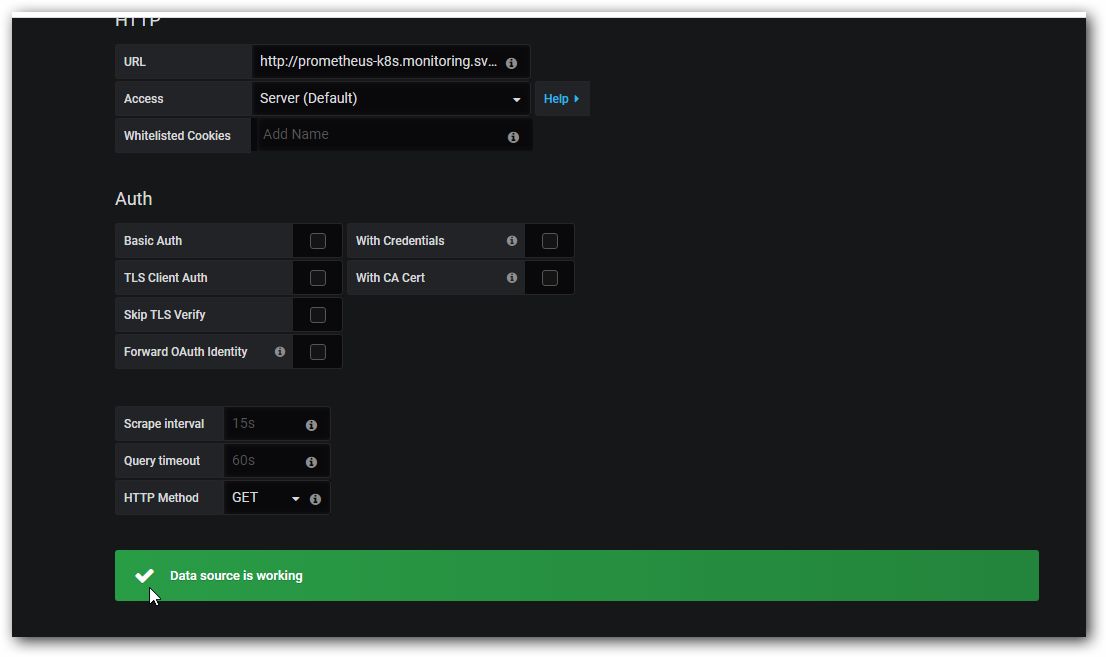
测试完好
添加插件

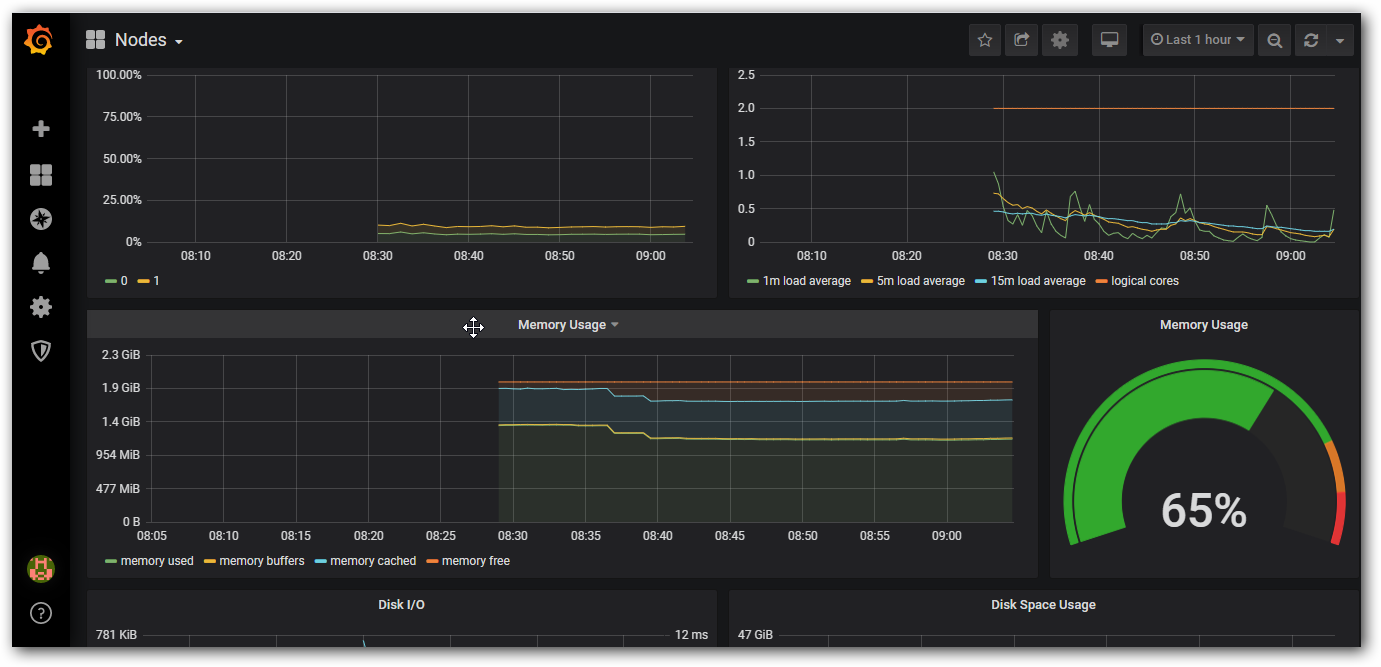
这样我们的数据可以正常显示

微信扫描 获取更多学习资料