
Python线程管理
阅读 (244160)一、线程
1、概念
-
线程
是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。在Unix System V及SunOS中也被称为轻量进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程
-
多线程
是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。具有这种能力的系统包括对称多处理机、多核心处理器以及芯片级多处理(Chip-level multithreading)或同时多线程(Simultaneous multithreading)处理器。
-
模块
_thread模块:低级模块
threading模块:高级模块,对_thread进行了封装
2、启动线程实现多任务
import time
import threading
def run1():
# 线程名字
print("启动%s子线程……"%(threading.current_thread().name))
for i in range(5):
print("zutuanxue_com is a good man")
time.sleep(1)
def run2(name, word):
print("启动%s子线程……" % (threading.current_thread().name))
for i in range(5):
print("%s is a %s man"%(name, word))
time.sleep(1)
if __name__ == "__main__":
t1 = time.clock()
# 主进程中默认有一个线程,称为主线程(父线程)
# 主线程一般作为调度而存在,不具体实现业务逻辑
# 创建子线程
# name参数可以设置线程的名称,如果不设置按顺序设置为Thread-n
th1 = threading.Thread(target=run1, name="th1")
th2 = threading.Thread(target=run2, args=("kaige", "nice"))
#启动
th1.start()
th2.start()
#等待子线程结束
th1.join()
th2.join()
t2 = time.clock()
print("耗时:%.2f"%(t2-t1))
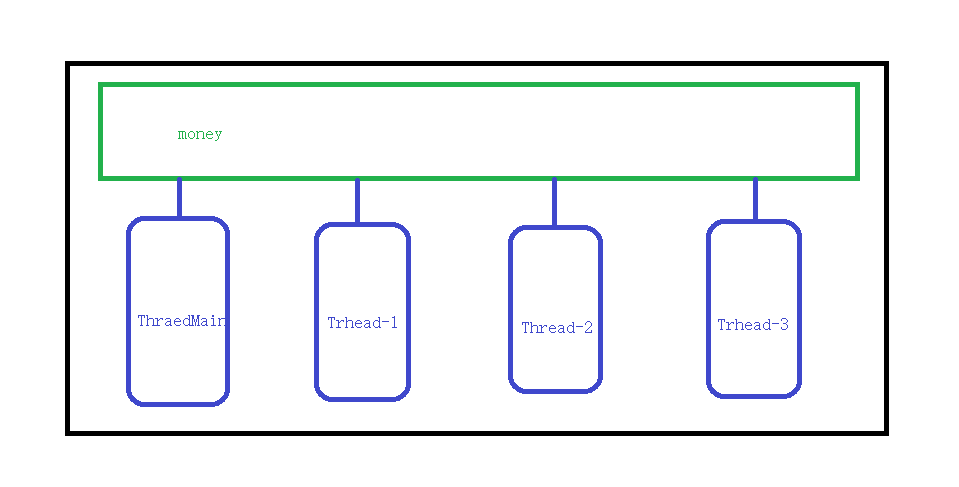
3、线程间共享数据
import time
import threading
money = 0
def run1():
global money
money = 1
print("run1-----------", money)
print("启动%s子线程……"%(threading.current_thread().name))
for i in range(5):
print("zutuanxue_com is a good man")
time.sleep(1)
def run2(name, word):
print("run2-----------", money)
print("启动%s子线程……" % (threading.current_thread().name))
for i in range(5):
print("%s is a %s man"%(name, word))
time.sleep(1)
if __name__ == "__main__":
t1 = time.clock()
th1 = threading.Thread(target=run1, name="th1")
th2 = threading.Thread(target=run2, args=("kaige", "nice"))
th1.start()
th2.start()
th1.join()
th2.join()
t2 = time.clock()
print("耗时:%.2f"%(t2-t1))
print("main-----------", money)
说明:多线程和多进程的最大的不同在于多进程中同一个全局变量每个子进程各自有一份拷贝,相互不影响。而在多线程中,所有变量都由线程共享
注意:多个线程同时修改一个变量容易内存错乱,下节课我们将进行演示
4、多线程内存错乱问题
import time
import threading
money = 0
def change_money(n):
global money
money += n
money -= n
def run1():
for i in range(1000000):
change_money(5)
def run2():
for i in range(1000000):
change_money(9)
if __name__ == "__main__":
t1 = time.clock()
th1 = threading.Thread(target=run1)
th2 = threading.Thread(target=run2)
th1.start()
th2.start()
th1.join()
th2.join()
t2 = time.clock()
print("耗时:%.2f"%(t2-t1))
print("main-----------", money)
问题:两个线程对同一数据同时进行读写,可能造成数据值的不对,我们必须保证一个线程在修改money时其他的线程一定不能修改,线程锁解决数据混乱问题
import time
import threading
#锁对象
lock = threading.Lock()
money = 0
def change_money(n):
global money
money += n
money -= n
def run1():
for i in range(1000000):
#获取线程锁,如果已上锁,则阻塞
lock.acquire()
try:
change_money(5)
finally:
#释放锁:千万要注意释放锁(自己的锁自己放),否则会造成死锁
lock.release()
def run2():
for i in range(1000000):
#简写,功能与上面一致
with lock:
change_money(9)
if __name__ == "__main__":
t1 = time.clock()
th1 = threading.Thread(target=run1)
th2 = threading.Thread(target=run2)
th1.start()
th2.start()
th1.join()
th2.join()
t2 = time.clock()
print("耗时:%.2f"%(t2-t1))
print("main-----------", money)
5、Thread Local
得到一个ThreadLocal对象,可以为每个线程提供独立的存储空间,每个线程都可以对它进行读写操作,但是相互不影响
import time
import threading
local = threading.local()
def run1():
local.money = 1
print("run1-----------", local.money)
time.sleep(1)
def run2():
time.sleep(2)
local.money = 2
print("run2-------------", local.money)
if __name__ == "__main__":
t1 = time.clock()
th1 = threading.Thread(target=run1)
th2 = threading.Thread(target=run2)
th1.start()
th2.start()
th1.join()
th2.join()
t2 = time.clock()
print("耗时:%.2f"%(t2-t1))
6、封装线程
zutuanxue_com_thread.py
import threading
class Zutuanxue_comThread(threading.Thread):
def __init__(self, num):
super().__init__()
self.num = num
def run(self):
print("-----------", self.num)
main.py
from zutuanxue_com_thread import Zutuanxue_comThread
if __name__ == "__main__":
th = Zutuanxue_comThread(1)
th.start()
th.join()
7、线程通信
-
通信原理
import threading def run(event): for i in range(10): event.wait() print("----------", i) event.clear() if __name__ == "__main__": event = threading.Event() th = threading.Thread(target=run, args=(event,)) th.start() for i in range(10): value = input() if value == "y": # 让线程运行一下 event.set() th.join() -
生产者与消费者
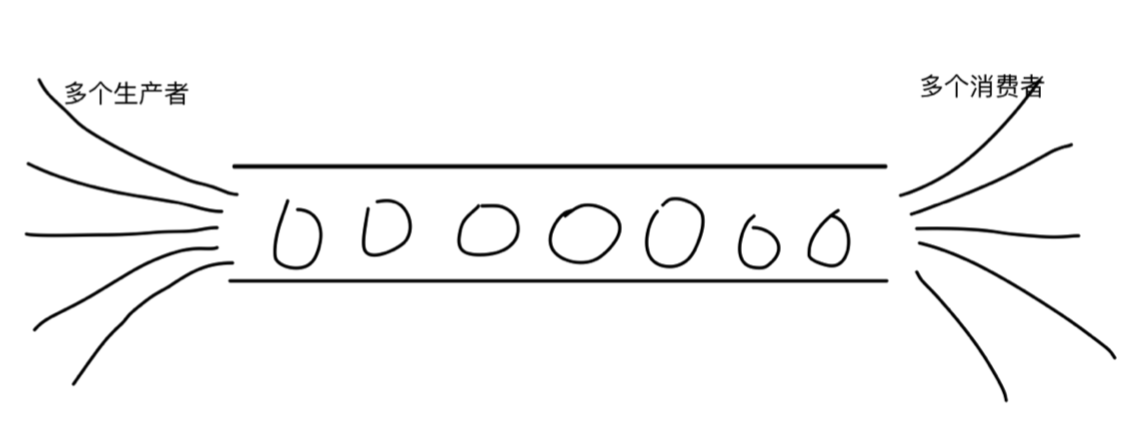
import threading
import time
def product(q,e):
print("启动生产子线程……")
for data in ["good", "nice", "cool", "handsome"]:
time.sleep(2)
print("生产出:%s"%data)
# 将生产的数据写入队列
q.append(data)
e.set()
print("发送结束信号")
time.sleep(2)
e.set()
print("结束生产子线程……")
def customer(q,e):
print("启动消费子线程……")
while 1:
print("等待生产者生产数据")
e.wait()
if len(q) == 0:
break
else:
value = q.pop()
print("消费者消费了%s数据"%(value))
e.clear()
print("结束消费子线程……")
if __name__ == "__main__":
q = []
e = threading.Event()
p1 = threading.Thread(target=product, args=(q,e))
p2 = threading.Thread(target=customer, args=(q,e))
p1.start()
p2.start()
p1.join()
p2.join()
print("END")
二、进程VS线程
-
多任务的实现原理
通常我们会设计Master-Worker模式,Master负责分配任务,Worker负责执行任务,因此,多任务环境下,通常是一个Master,多个Worker
-
多进程
主进程就是Master,其他进程就是Worker
-
优点
稳定性高:一个子进程崩溃了,不会影响主进程和其他子进程,当然主进程挂了所有进程就全挂了,但是Master进程只负责分配任务,挂掉的概率低
-
缺点
创建进程的代价大:在Unix/Linux系统下,用fork调用还行,在Windows下创建进程开销巨大
操作系统能同时运行的进程数也是有限的:在内存和CPU的限制下,如果有几千个进程同时运行,操作系统连调度都会成问题
-
-
多线程
主线程就是Master,其他线程就是Worker
-
优点
多线程模式通常比多进程快一点,但是也快不到哪去
在Windows下,多线程的效率比多进程要高
-
缺点
任何一个线程挂掉都可能直接造成整个进程崩溃:所有线程共享进程的内存。在Windows上,如果一个线程执行的代码出了问题,你经常可以看到这样的提示:“该程序执行了非法操作,即将关闭”,其实往往是某个线程出了问题,但是操作系统会强制结束整个进程
-
-
计算密集型 vs IO密集型
-
计算密集型
要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数
-
IO密集型
涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用
-

微信扫描 获取更多学习资料