
雪崩效应和主流的容错项目
阅读 (3454548)
分享
1、雪崩效应
1.1、什么是雪崩效应
在微服务架构中,服务之间通常存在级联调用。比如,服务A调用服务B,而服务B需要调用服务C,而服务C又需要调用服务D。如果其中任意一点不可用,或者存在响应延时,则可能造成很多服务不可用,即产生级联故障。
“服务提供者”不可用导致"服务消费者"不可用并将不可用逐渐放大到整个微服务系统,进而造成系统崩溃。
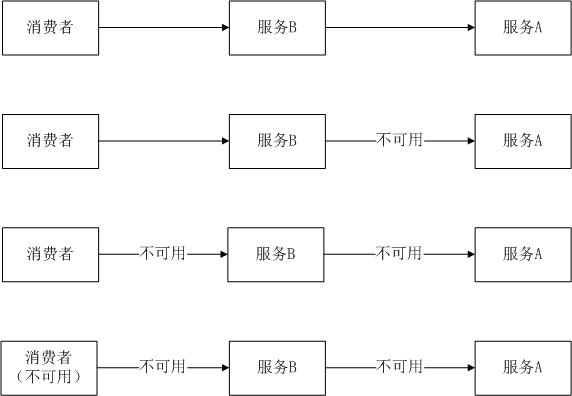
1.2、造成雪崩的原因
1.2.1、流量激增
**例如:**新闻事件、促销活动、恶意功击等。
1.2.2、硬件故障
例如: 单点的硬件损坏使得集群的服务压力加大,从而出现服务延迟,服务延迟不断加剧导致雪崩。
1.2.3、程序中的Bug
**例如:**程序中有循环调用等逻辑问题,或者资源未释放引起的内存泄漏。
1.2.4、缓存问题
**例如:**缓存穿透、缓存击穿、缓存雪崩也可能导致服务雪崩。
1.2.5、配套资源不可用
**例如:**数据中心掉线,电信基础网络服务出现城市集群故障。
2、主流的容错项目
2.1、Sentinel
Sentinel是一款面向分布式服务架构的轻量级流量控制组件,根据设置的规则来为资源执行相应的流量控制、服务降级、系统保护策略。
2.2、容错框架Resilience4j
Resilience4j一个比较轻量级的、模块化的熔断降级库。它由熔断、限速器、自动重试等功能组成,这些功能都被拆分成了单独的模块,用户可以根据需要引入相应功能的依赖。
Resilience4j在较小的项目中使用比较方便,但是Resilience4j只适用于限流降级的基本场景,无法适用于非常复杂的企业级服务架构。
2.3、容错框架Hystrix
Hystrix是由Netflix开源的一款容错框架,包含隔离、熔断、降级回退和缓存容错、缓存、批量处理请求、主从分担等常用功能。

微信扫描 获取更多学习资料
需要
登录
才可以提问哦
: